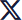While transitioning to a microservices architecture can offer numerous benefits for your business, it is not a decision that should be taken lightly. It requires careful planning, a clear understanding of the existing system, and a commitment to addressing the challenges that come with a new architectural style. However, when done right, it can lead to greater agility, scalability, and the ability to respond to changing business needs more effectively.
This article refrains from discussing the circumstances or decision-making process leading up to the breakdown of a monolithic system. Instead, it outlines the methodical approach to effectively decompose such service monoliths once the decision has already been made.
Bounded context
It’s important to understand bounded context, also known as seams, before we start analyzing a monolith for decomposing into microservices. Bounded context is a well-defined, explicit boundary within a software system that encapsulates a specific domain and its business rules.
When we start to think about the bounded contexts in an organization, we should be thinking not about shared data but about the capabilities those contexts provide to the rest of the domain.
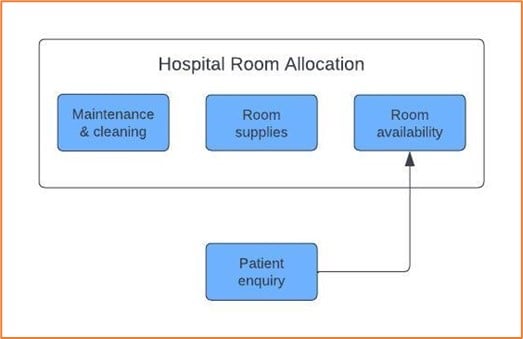
Figure 1: Bounded context example
Any microservice must have two most important characteristics:
- High cohesion: All related behavior sits together and is unrelated elsewhere
- Loose coupling: A change in one service should not require a change to another
Once we identify these service boundaries, also known as bounded contexts, these modular boundaries become excellent candidates for microservices.
Tangled dependencies
Once we have identified the seams that we can separate, pulling out the service that is relied on the least is a good place to start. Drawing a graph of the dependencies of all seams can help identify the seam that is most entangled and which one is the least.
The database
For the database, we follow the same approach that we followed for tangled dependencies. Find the seams or dependencies in the database to split them out. The way we grouped our code around bounded contexts is the same for access layers accessing the database.
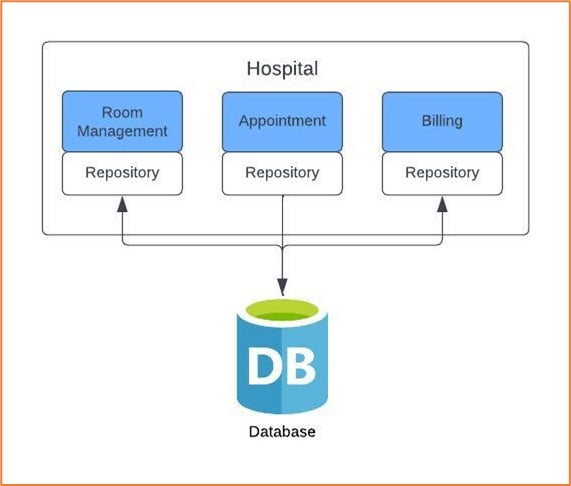
Figure 2: Example of splitting a database
Shared data
Let’s look at an example where a code updates the patient records to show if an appointment for the patient has been booked or not, the billing department tracks payments made by the patient, and all this data is displayed in one place on the website.
This is an example where the domain concept is not modeled into the code but implicitly modeled in the database. In this case, we can abstract out the patient and expose APIs to other services to consume.
Figure 3: Shared data example
Gradual deconstruction
We have grouped our code around bounded context, used it to identify seams in our database, and separated the access code into layers. Should we split the code into services and go for release?
We recommend splitting out the schema but keeping the services together for some time so that the service consumers are unaffected. This allows us to modify things or revert them without affecting the consumers.
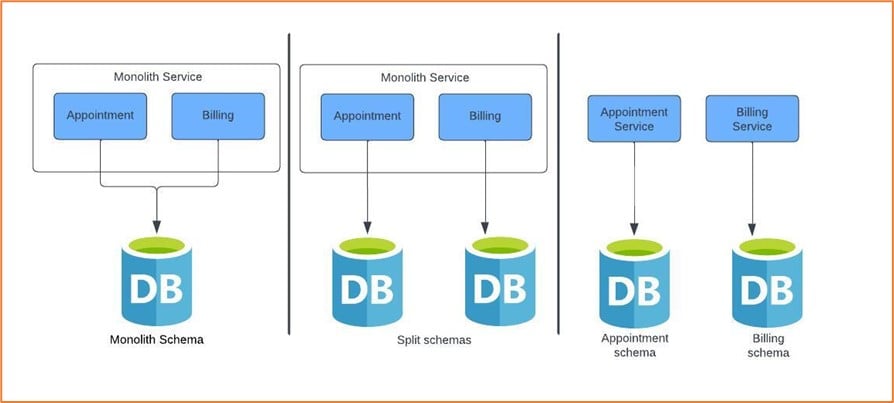
Figure 4: Gradual deconstruction example
Transactional boundaries
In a monolithic system, transactions such as updating multiple database records occur within a unified boundary. Microservices pose a challenge, as each service has its own transactional boundary.
For any such transaction to occur, the first question to ask is if the transaction really needs to. Distributed transactions are hard to get right, and they come with their own set of complexities. If there is a business operation that needs to happen within a transaction, be sure to:
- Make every effort to prevent an initial split from occurring
- Try the eventual consistency model
- Consider compensating transaction or two-phase commit mode
Consider a scenario where a patient makes an advance payment to book a room in a hospital. The entries need to be made in two tables: payment service and room allocation service. In a monolith system, this would take place in a single transaction. However, we have lost this transaction safety in a microservice architecture because of separate schemas. In this case, we can:
- Queue up this part of the operation and try again later—eventual consistency
- Issue a compensating transaction to roll back the entire operation
- Use a two-phase commit method where all participating transactions vote to commit or rollback
Reporting
Reporting in a monolith system was relatively easy, as data was stored in just one database. However, reporting in a microservice architecture needs the grouping of data from different services to generate a useful output.
A standard reporting database introduces tight coupling with the service database. Instead, we can emit events on every update on the service database and write those events to either the reporting database or any storage, like S3. If we store which events have already been processed, we can just process the new events as they arrive, assuming the old events have already been mapped into the reporting system.
This means our insertion will be more efficient, as we only need to send deltas. Using universal structures, like JSON, would eliminate the tight coupling of schemas between the source service and the reporting database.
Conclusion
Breaking down the monolith is a well-thought-out process, and the result can be immensely beneficial to your organization. It’s critical to follow an incremental approach in decomposing the system by finding the seams along which service boundaries can emerge.
The most important things to realize are that a system should be broken down before it gets too costly to split, and there comes a point when further breakdown of services isn’t beneficial. While each business is unique, and there is no one direct answer as to when that point is, there are several factors essential for any business to consider, including:
- Functional separation: The monolith has been broken down such that each service handles a well-defined business function.
- Business needs: Continuously assess whether the current state of services aligns with your business goals. If future decomposition doesn’t provide a clear advantage, it may be time to stop.
- Operational complexity: If the operational complexity of running and managing many microservices becomes overwhelming, it may be time to reevaluate, as each additional service will only add to the complexity.
For more information and guidance on deconstructing a monolith service architecture, please contact our team of experts.